
The technological advancements in diffusion models (DMs) have demonstrated unprecedented capabilities in text-to-image generation and are widely used in diverse applications. However, they have also raised significant societal concerns, such as the generation of harmful content and copyright disputes. Machine unlearning (MU) has emerged as a promising solution, capable of removing undesired generative capabilities from DMs. However, existing MU evaluation systems present several key challenges that can result in incomplete and inaccurate assessments. To address these issues, we propose UNLEARNCANVAS, a comprehensive highresolution stylized image dataset that facilitates the evaluation of the unlearning of artistic styles and associated objects. This dataset enables the establishment of a standardized, automated evaluation framework with 7 quantitative metrics assessing various aspects of the unlearning performance for DMs. Through extensive experiments, we benchmark 9 state-of-the-art MU methods for DMs, revealing novel insights into their strengths, weaknesses, and underlying mechanisms. Additionally, we explore challenging unlearning scenarios for DMs to evaluate worst-case performance against adversarial prompts, the unlearning of finer-scale concepts, and sequential unlearning. We hope that this study can pave the way for developing more effective, accurate, and robust DM unlearning methods, ensuring safer and more ethical applications of DMs in the future.
Figure: An illustration of the task Machine Unlearning for Diffusion Models. The pretrained model contains the generation capability of different concepts in different domains. MU aims to erase the generation of a certain unlearning target concept while retaining the generation of others.
To enhance the assessment of MU in DMs and establish a standardized evaluation framework, we propose to develop a new benchmark dataset, referred to as UnlearnCanvas, which is designed to evaluate the unlearning of artistic painting styles along with associated image objects.
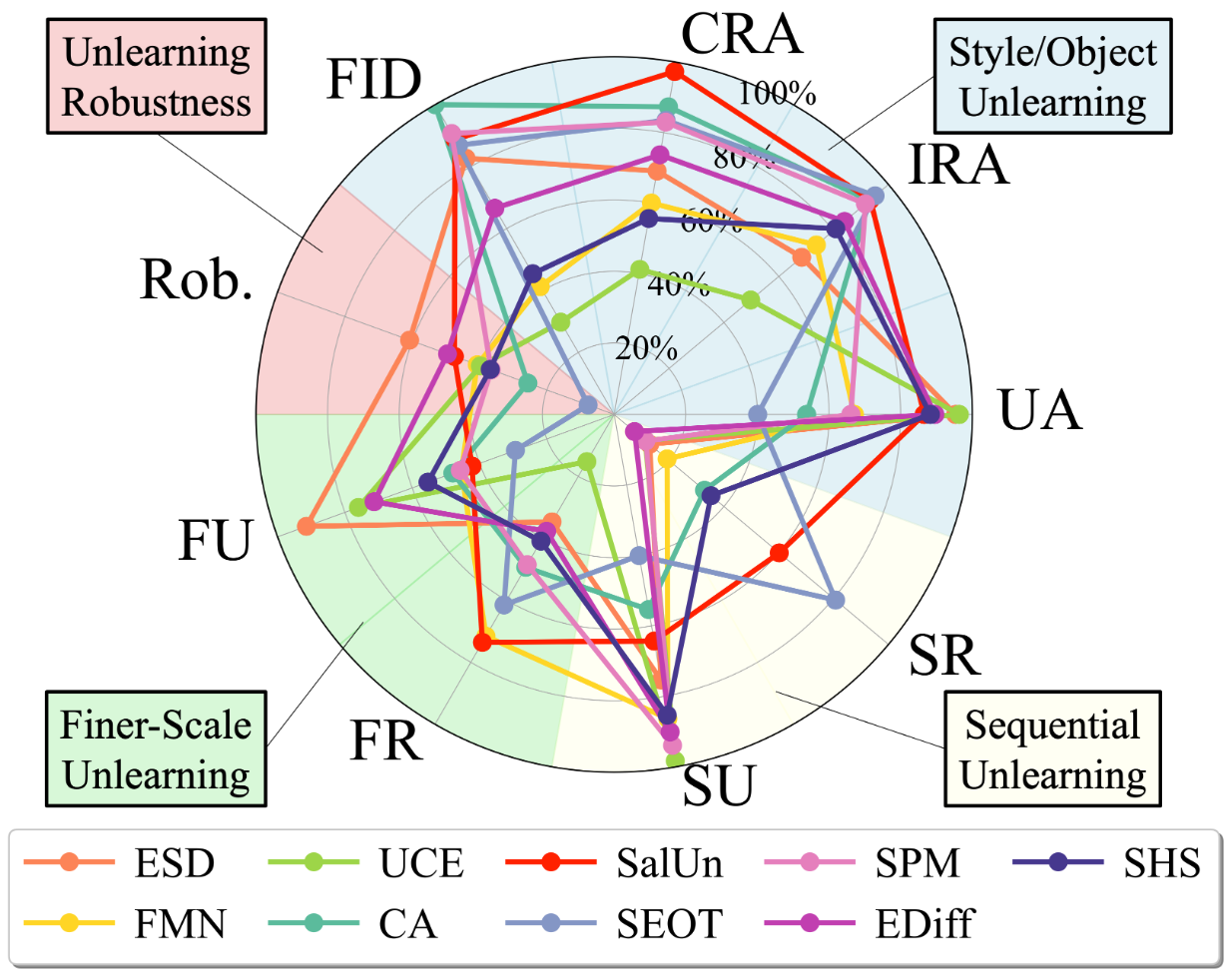
Figure: An overview of experiment settings and benchmark results. This benchmark focuses on three categories of quantitative metrics: the unlearning effectiveness (UA, Rob., FU, SU); the retainability of innocent knowledge (IRA, CRA, FR, SR); and theimage generation quality (FID). Results are normalized to 0% ∼ 100% per metric. No single method excels across all metrics.
We benchmark 9 state-of-the-art DM unlearning methods using UnlearnCanvas, covering standard assessments and examining more challenging scenarios, such as adversarial robustness, grouped object-style unlearning, and sequential unlearning. This comprehensive evaluation provides previously unknown insights into their strengths and weaknesses.
We started by examining the existing MU evaluation methods and uncovered several key challenges that can result in incomplete, inaccurate, or biased evaluations for MU in DMs.
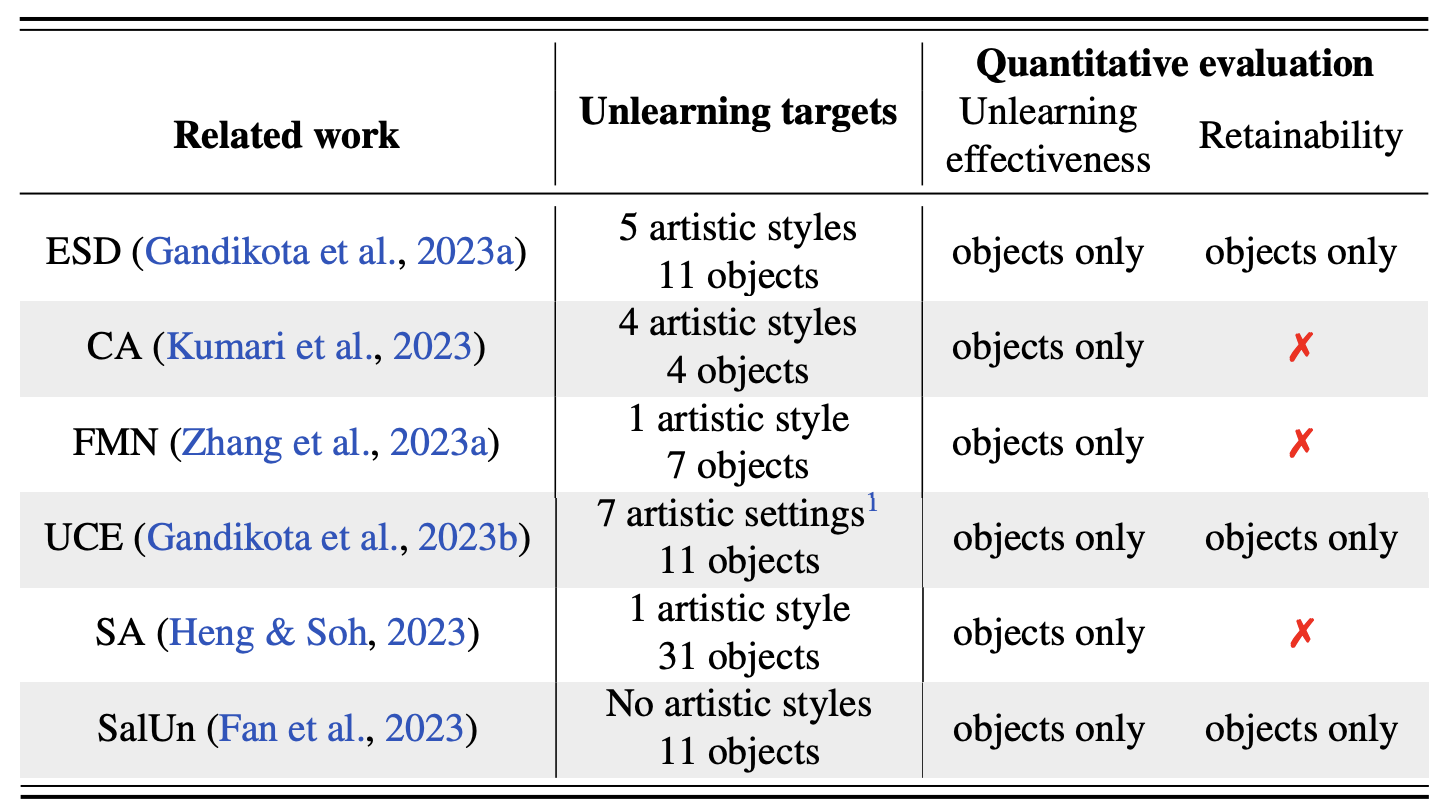
Table: An overview of the scope and evaluation methods of the existing MU methods for DMs.
Challenge I: The absence of a diverse yet cohesive unlearning target repository. The assessment of MU for DMs, in terms of both effectiveness (concept erasure performance) and retainability (preserved generation quality under non-forgotten concepts), is typically conducted using manually selected targets, often chosen from a limited pool of unlearning targets.
Challenge II: The lack of precision in evaluation. Artistic styles can be challenging to precisely define and distinguish, which makes quantifying their impact on unlearning effectiveness and retainability difficult.
Challenge III: The lack of a systematic study on ‘retainability’ of DMs post unlearning. As indicated by the table above, assessing the capacity of unlearned DMs to maintain image generation under innocent concepts is notably lacking, known as the quantitative evaluation of the ‘retainability’.
UnlearnCanvas is created for ease of MU evaluation in DMs. Its construction involves two main steps: seed image collection and subsequent image stylization.
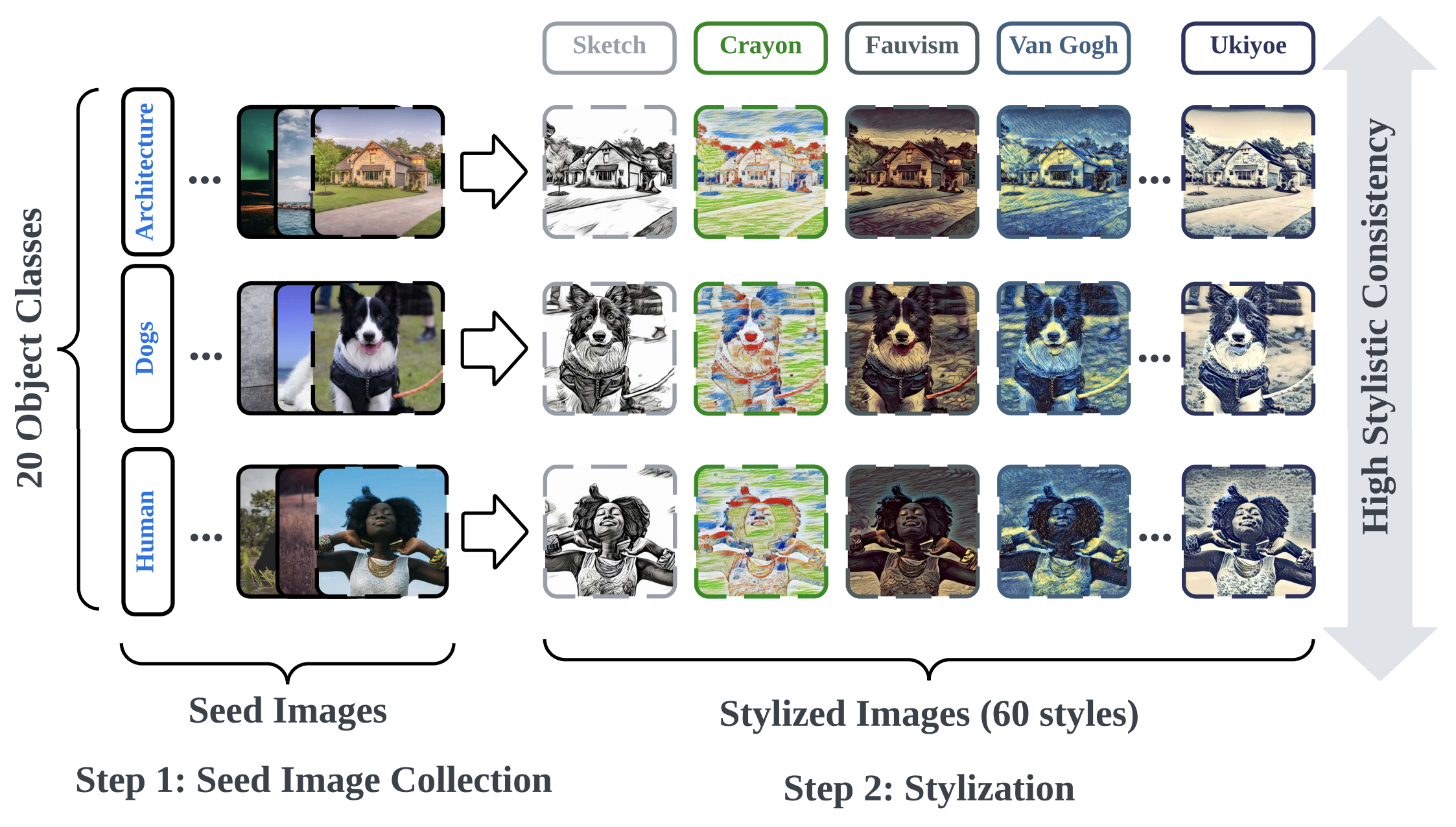
Figure: An illustration of the key steps when curating UnlearnCanvas and its key features.
Advantages of UnlearnCanvas.
A1: Style-object dual supervision enables a rich unlearning target bank for comprehensive evaluation.
A2: High stylistic consistency ensures precise style definitions and enables accurate quantitative evaluations.
A3: Enabling in-depth retainability analyses for MU evaluation.
Key features of UnlearnCanvas:
High-Resolution
Dual-Supervised
Balanced Dataset
High stylistic consistent within each style.
High stylistic distinction across different styles.
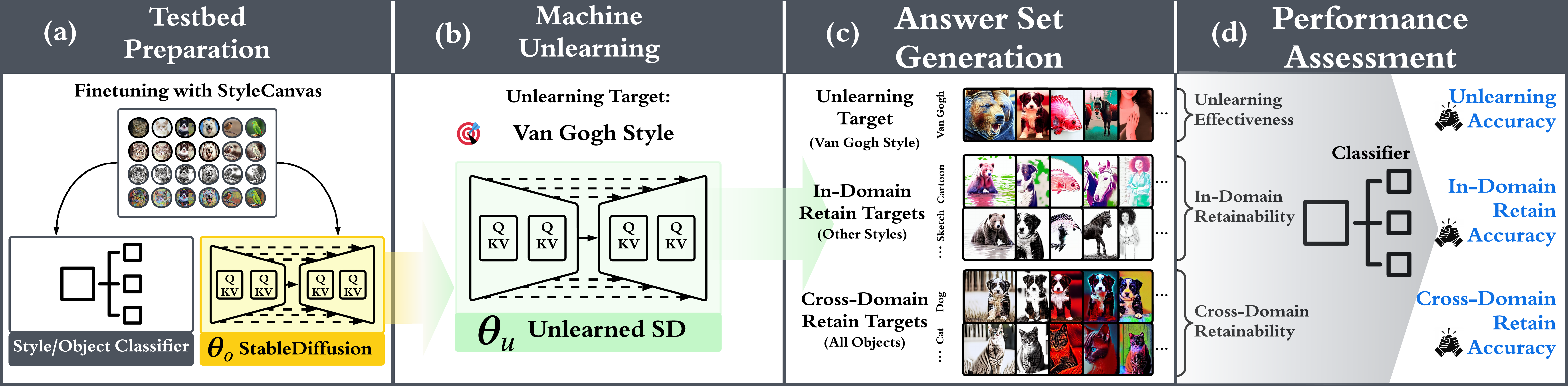
Figure: An illustration of the key steps when curating UnlearnCanvas and its key features.
We introduce the evaluation pipeline and the benchmarked MU methods with UnlearnCanvas, which comprises four phases (I-IV) to evaluate unlearning effectiveness, retainability, generation quality, and efficiency.
Phase I: Testbed preparation. We commence by fine-tuning a specific DM, given by SD v1.5 on UnlearnCanvas for text-to-image generation, and a ViT-Large for style and object classification after unlearning.
Phase II: Machine unlearning. We utilize the selected MU methods for benchmarking to update the DM acquired in Phase I, aiming to eliminate a designated unlearning target.
Phase III: Answer set generation. We utilize the unlearned model to generate a set of images conditioned on both the unlearning-related prompts and other innocent prompts. For comprehensive evaluation, three types of answer sets are generated: for unlearning effectiveness, in-domain retainability, and cross-domain retainability evaluation.
Phase IV: Answer set generation. The answer set undergoes style/object classification for unlearning performance assessment. This classification results in three quantitative metrics: unlearning accuracy, in-domain retaining accuracy, and cross-domain retaining accuracy.
Our benchmarking results are divided into two main parts.
First, we comprehensively evaluate the existing DM unlearning methods on the established tasks of style and object unlearning. Extensive studies following the proposed evaluation pipeline reveal that focusing solely on unlearning effectiveness can lead to a biased perspective for DM unlearning if retainability is not concurrently assessed. We also show that preserving CRA (cross-domain retainability) is more challenging than IRA (in-domain retainability), highlighting a gap in the current literature. Furthermore, we find that different DM unlearning methods exhibit distinct unlearning mechanisms by examining their unlearning directions.
Second, we introduce more challenging unlearning scenarios. (1) We assess the robustness of current DM unlearning methods against adversarial prompts. (2) We examine the performance when facing unlearning targets with finer granularity, formed by style-object concept combinations. (3) We leverage UnlearnCanvas to provide insights into DM unlearning in a sequential unlearning fashion.
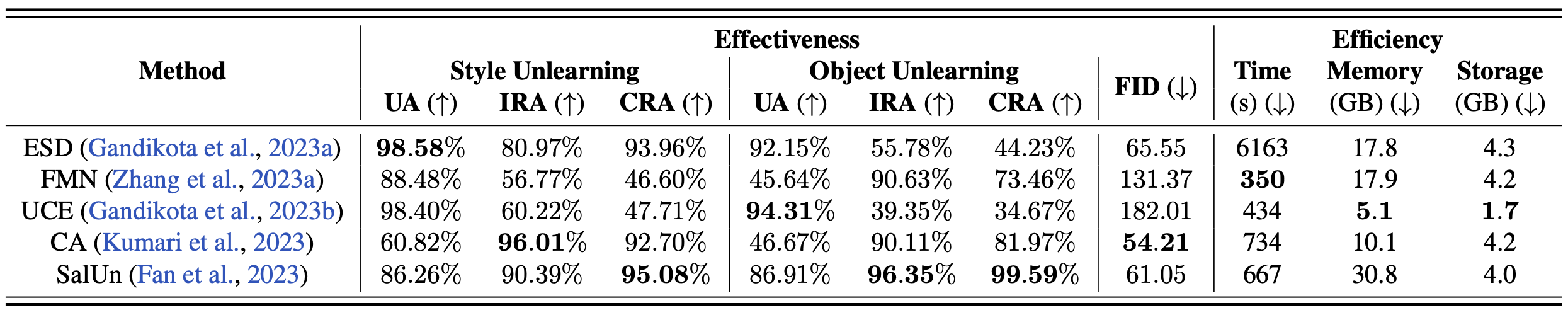
Table: Performance overview of different MU methods evaluated with UnlearnCanvas dataset. The performance assessment includes unlearning accuracy (UA), in-domain retain accuracy (IRA), cross-domain retain accuracy CRA), and FID. Symbols ↑ or ↓ denote whether larger or smaller values represent better performance. Results are averaged over all the style and object unlearning cases. The best performance regarding each metric is highlighted in bold.
(1) Retainability is essential for comprehensive assessment of MU in DMs.
(2) CRA (cross-domain retaining accuracy) is harder to retain than IRA (in-domain retaining accuracy).
(3) One MU method can perform differently in different domains.
(4) No single method can excel in all aspects.
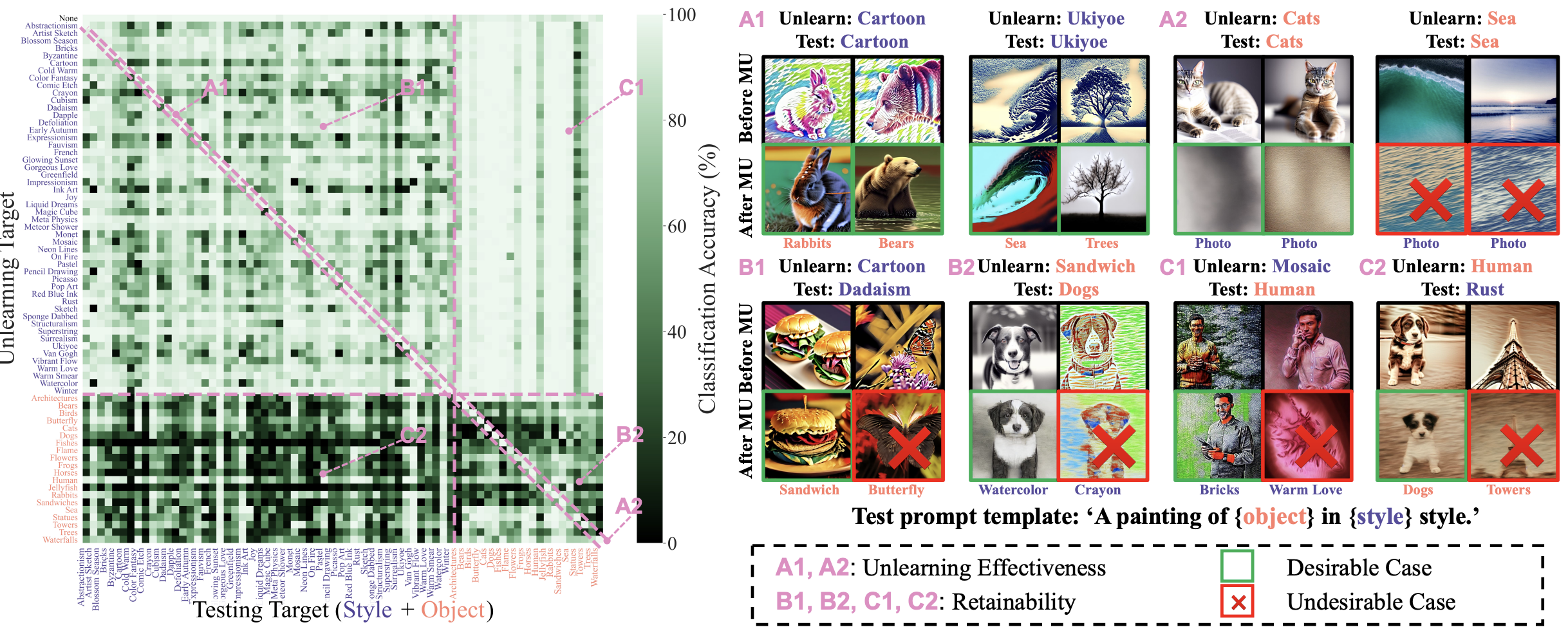
Figure: Left: Heatmap visualization of the unlearning and retain accuracy of ESD on UnlearnCanvas. The x-axis shows the tested concepts for image generation using the unlearned model, while the y-axis indicates the unlearning target. Concept types are distinguished by color: styles in blue and objects in orange. The figure is separated into different regions to represent corresponding evaluation metrics and the unlearning scopes (A for UA, B for IRA, C for CRA; ‘1’ for style unlearning, ‘2’ for object unlearning). Diagonal regions (A1 and A2) indicate unlearning accuracy, and off-diagonal values (B1, B2, C1, and C2) represent retain accuracy. Higher values in lighter color denote better performance. The first row serves as a reference for comparison before unlearning. Zooming into the figure is recommended for detailed observation. Right: Representative cases illustrating each region with images generated before and after unlearning a specific concept..
(1) An MU method might demonstrate a preference within a specific domain but face challenges in others.
(2) Style/Object unlearning is relatively easier compared to retaining the generation performance of unlearned DMs conditioned on unlearning-unrelated prompts.
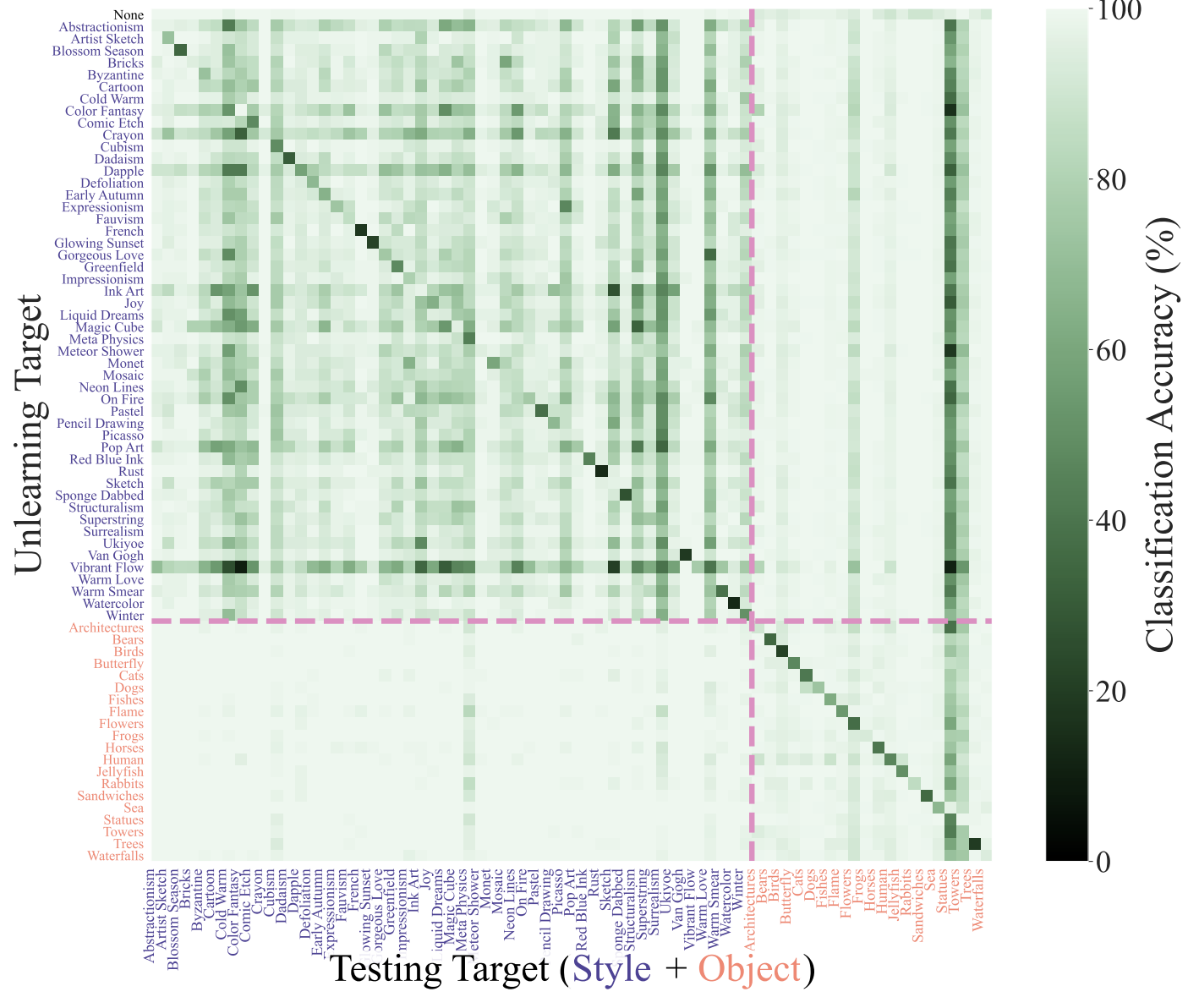
Figure: Heatmap visualization of SalUn..
(3) In comparison to ESD, SalUn demonstrates more consistent performance across different unlearning scenarios. However, SalUn does not achieve the same level of UA as ESD, as evidenced by the lighter diagonal values
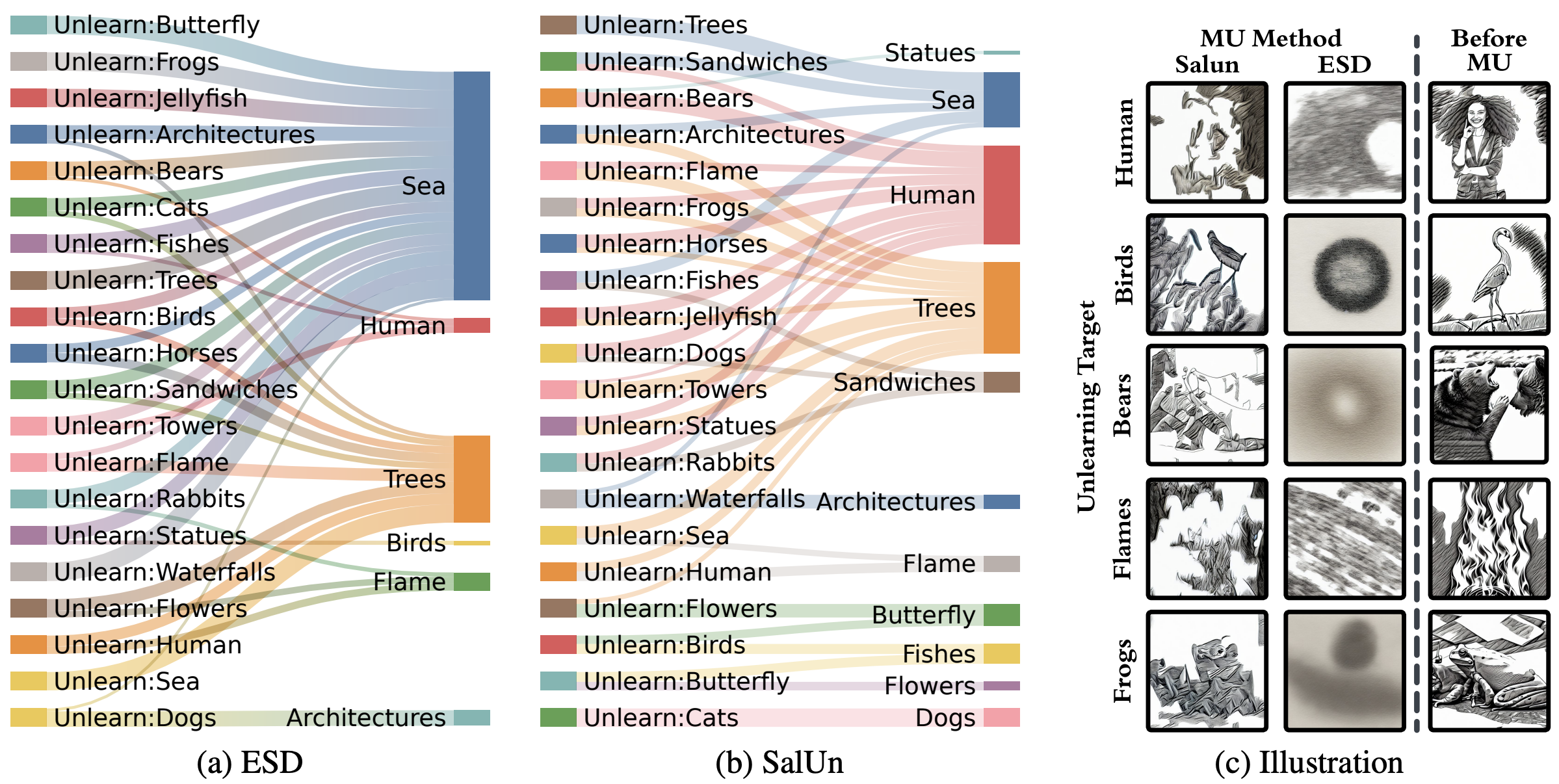
Figure: Visualization of the unlearning directions of (a) ESD and (b) SalUn. This figure illustrates the conceptual shift of the generated images of an unlearned model conditioned on the unlearning target. Images generated by the post-unlearning models are classified and used to understand this shift. Edges leading from the object in the left column to the right signify that images generated conditioned on unlearning targets are instead classified as the shifted concepts after unlearning. This reveals the primary unlearning direction for each unlearning method. The most dominant unlearning direction for an object is visualized. Figure (c) provides visualizations of generated images using the prompt template ‘A painting of {object} in Sketch style.’ with object being each unlearning target.
Different unlearning methods display distinct unlearning behaviors. These unlearning directions are determined by connecting the unlearning target with the predicted label of the generated image from the unlearned DM conditioned on the unlearning target.
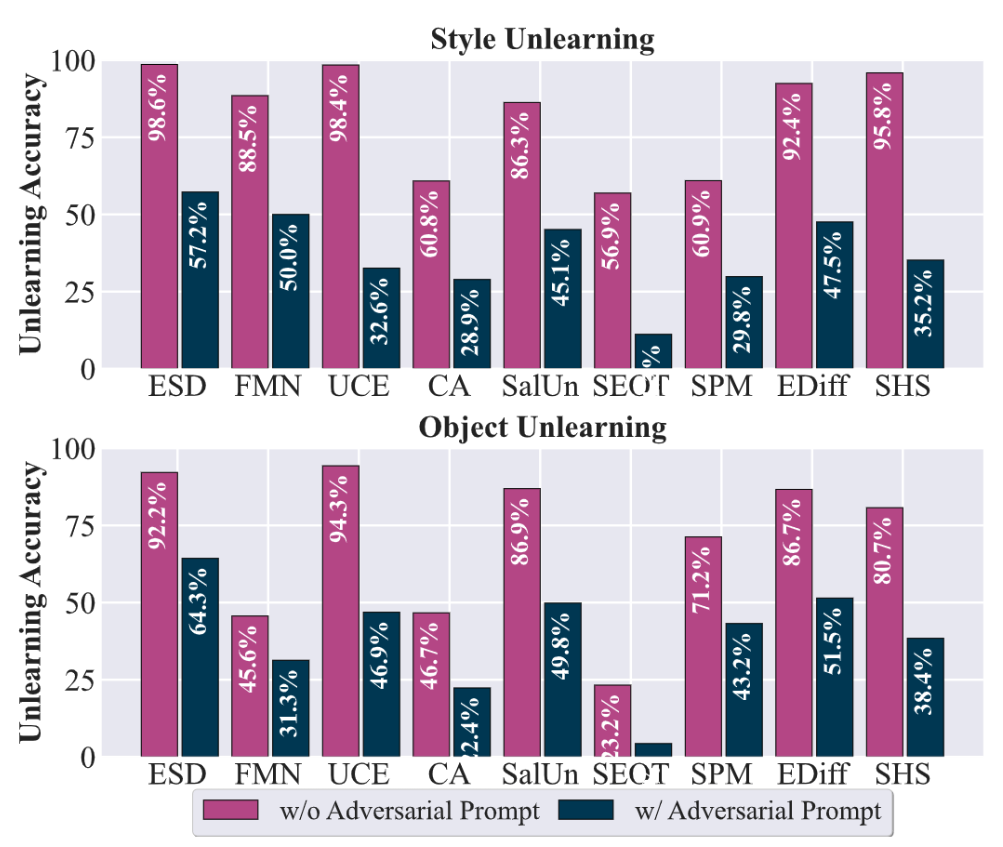
Figure: Unlearning accuracy of DM unlearning against adversarial prompts. Unlearned models in the style and object unlearning scenarios are used as victim models to generate adversarial prompts.
All the DM unlearning methods experience a significant drop in UA, falling below 60% when confronted with adversarial prompts. Notably, methods like UCE, SEOT, and SHS exhibit particularly steep declines. Moreover, a high UA under normal conditions does not necessarily imply robustness to adversarial attacks. For instance, although UCE achieves a UA over 90% in normal settings, its performance plummets to below 50% against adversarial prompts. This stark contrast highlights the importance of the worst-case evaluation for MU methods.
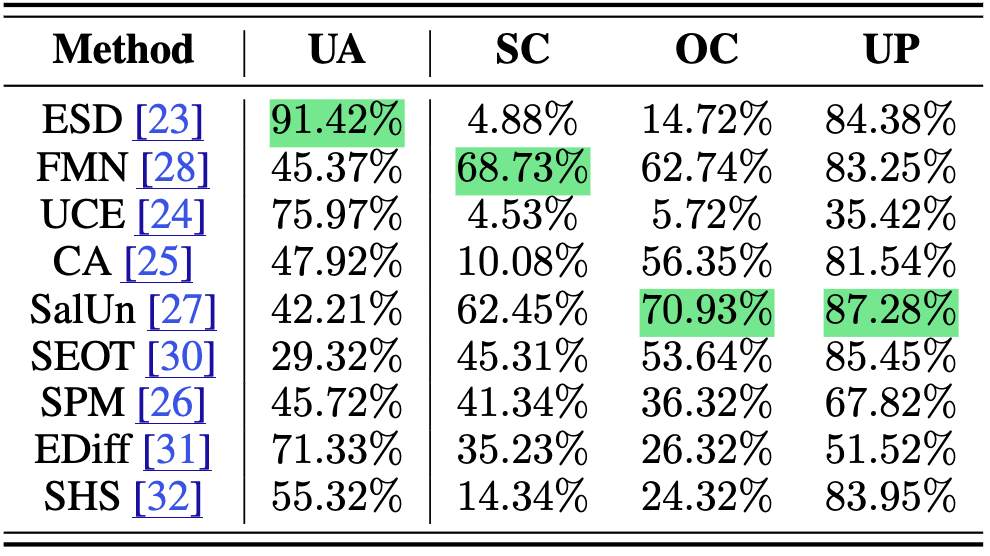
Figure: Performance of unlearning style-object combinations. The assessment includes UA and retainability in three contexts: SC (style consistency), OC (object consistency), and UP (unrelated prompting). The best result in each metric is highlighted in green.
Experiment Settings: We consider the fine granularity of the unlearning target, defined by a style-object combination, such as “An image of dogs in Van Gogh style”. This unlearning challenge requires the unlearned model to avoid affecting image generation for dogs in non-Van Gogh styles and Van Gogh-style images with non-dog objects.
Evaluation Metrics: Besides UA, the retainability performance is assessed in three contexts. (a) Style consistency (SC): retainability under prompts with different objects but in the same style, e.g., “An image of cats in Van Gogh style”. (b) Object consistency (OC): retainability under prompts featuring the same object in different styles, e.g., “An image of dogs in Picasso style”. (c) Unrelated prompting (UP): retainability for all other prompts.
Conclusion: Style-object combinations are more challenging to unlearn than individual objects or styles, as evidenced by a significant drop in UA—over 20% lower compared to values in Tab. 2. Retainability drops to below 20% for topperforming methods like ESD and UCE, originally highlighted for their efficacy. This is presumably due to ESD’s underlying unlearning mechanism, which requires only a single prompt, resulting in a poor ability to precisely define the unlearning scope.
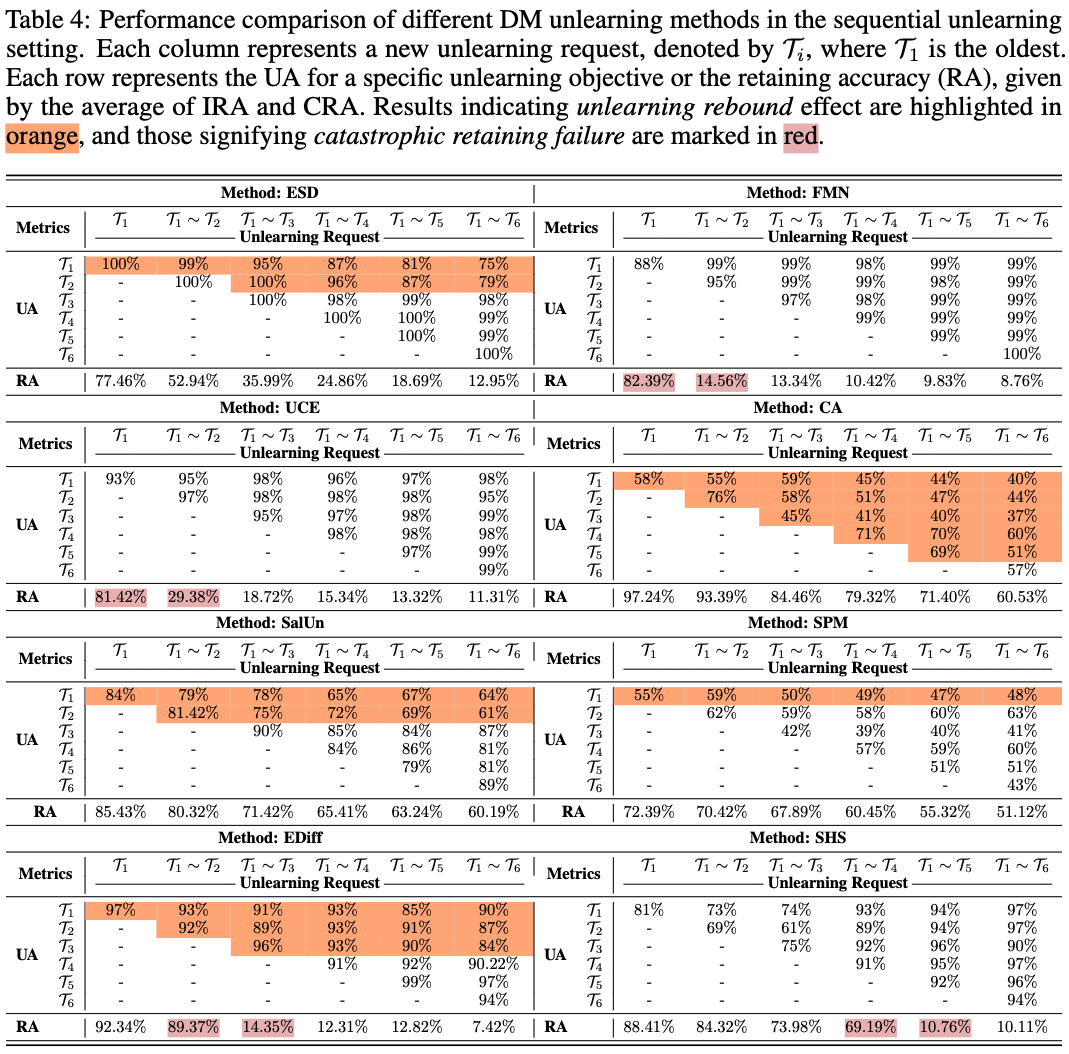
Table: Performance comparison of different DM unlearning methods in the sequential unlearning setting. Each column represents a new unlearning request, denoted by Ti, where T1 is the oldest. Each row represents the UA for a specific unlearning objective or the retaining accuracy (RA), given by the average of IRA and CRA. Results indicating unlearning rebound effect are highlighted in orange, and those signifying catastrophic retaining failure are marked in red.
Experiment Settings: we evaluate the unlearning performance in sequential unlearning (SU), where unlearning requests arrive sequentially. This parallels the continual learning task, which requires models to not only unlearn new targets effectively but also maintain the unlearning of previous targets while retaining all other knowledge. Here, we consider unlearning 6 styles sequentially.
Conclusion: Our findings reveal significant insights.
(1) Degraded retainability: Sequential unlearning requests generally degrade retainability across all methods, with RA values frequently dropping below the average levels previously seen.
(2) Unlearning rebound effect: Knowledge previously unlearned can be inadvertently reactivated by new unlearning requests.
(3) RA significantly drops at a certain request, exemplified by a sudden decrease in RA of UCE from 81.42% to 29.38% after the second request.
 |
Y. Zhang, C. Fan, Y. Zhang, Y. Yao, J. Jia, J. Liu, G. Zhang, G. Liu, R. R. Kompella, X. Liu, S. Liu. UnlearnCanvas: A Stylized Image Dataset to Benchmark Machine Unlearning for Diffusion Models (hosted on ArXiv) |
@article{zhang2024unlearncanvas,
title={Unlearncanvas: A stylized image dataset to benchmark machine unlearning for diffusion models},
author={Zhang, Yihua and Fan, Chongyu and Zhang, Yimeng and Yao, Yuguang and Jia, Jinghan and Liu, Jiancheng and Zhang, Gaoyuan and Liu, Gaowen and Rao Kompella, Ramana and Liu, Xiaoming and Liu, Sijia},
journal={arXiv preprint arXiv:2402.11846},
year={2024}
}